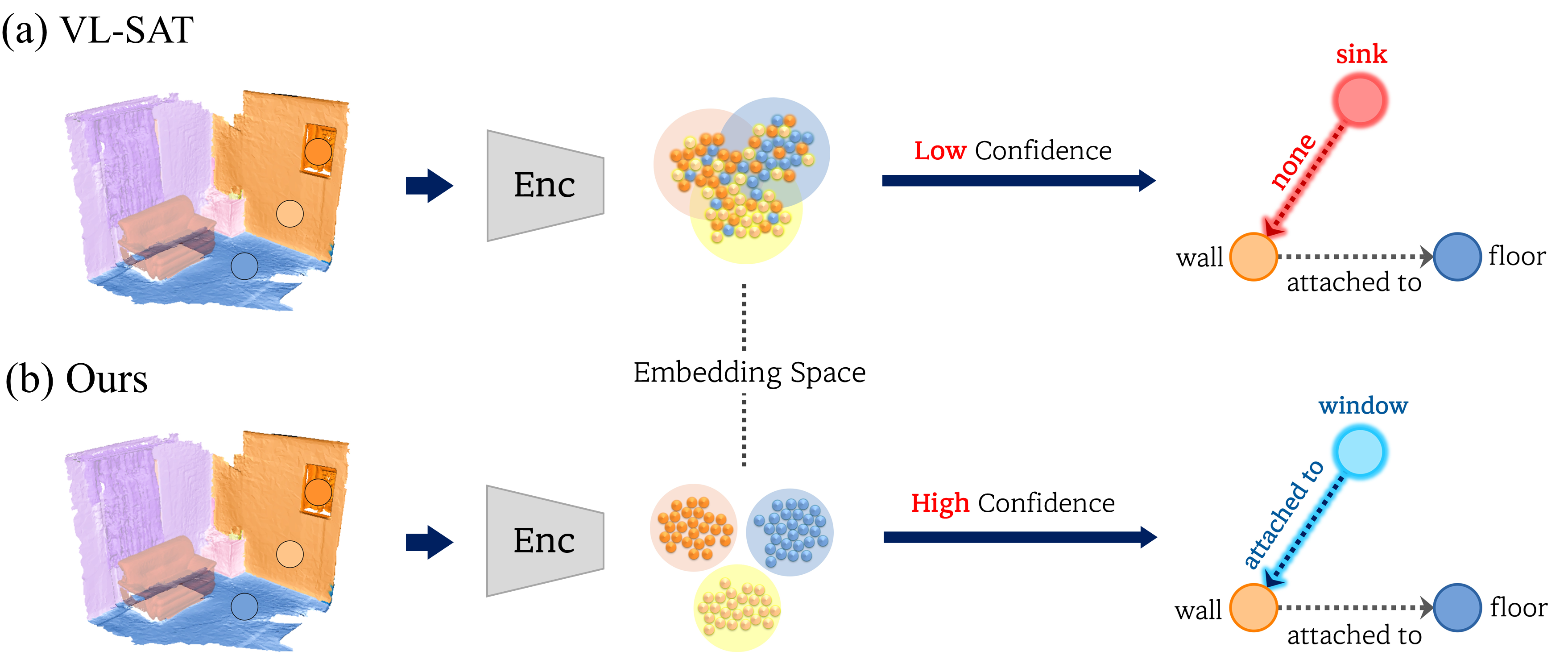
 TD;LR: We observe that the primary bottleneck in 3D semantic scene graph prediction lies in object representation, which directly impacts the accuracy of predicate reasoning. (a) Baseline (VL-SAT) embeds object features non-discriminatively, leading to low-confidence
predictions and frequent object misclassifications, which degrade relationship accuracy. In contrast,
(b) our method embeds object features in a more discriminative manner, yielding high confidence
scores and more accurate object classifications. Consequently, relationship predictions are significantly improved, resulting in a more coherent and semantically accurate scene graph.
TD;LR: We observe that the primary bottleneck in 3D semantic scene graph prediction lies in object representation, which directly impacts the accuracy of predicate reasoning. (a) Baseline (VL-SAT) embeds object features non-discriminatively, leading to low-confidence
predictions and frequent object misclassifications, which degrade relationship accuracy. In contrast,
(b) our method embeds object features in a more discriminative manner, yielding high confidence
scores and more accurate object classifications. Consequently, relationship predictions are significantly improved, resulting in a more coherent and semantically accurate scene graph.
Abstract
Core Contributions
- We identify the overlooked importance of object representation in prior 3DSSG methods and propose a Discriminative Object Feature Encoder, pretrained independently to serve as a robust semantic foundation—improving not only our model but also enhancing performance when integrated into existing frameworks.
- A novel Relationship Feature Encoder that combines object pair embeddings with geometric relationship information, enhanced by LSE
- A Bidirectional Edge Gating mechanism that explicitly models subject-object asymmetry, along with a Global Spatial Enhancement to incorporate holistic spatial context
- We validate our approach through extensive experiments, achieving significant performance improvements over state-of-the-art 3DSSG methods.
Proposed Method
We propose a two-stage training framework for 3D semantic scene graph prediction. In the first stage, we pretrain an object encoder to learn discriminative object-level feature representations. In the second stage, we predict the full 3D scene graph using a graph neural network equipped with our proposed components: Bidirectional Edge Gating (BEG), Local Spatial Enhancement (LSE), and Global Spatial Enhancement (GSE).
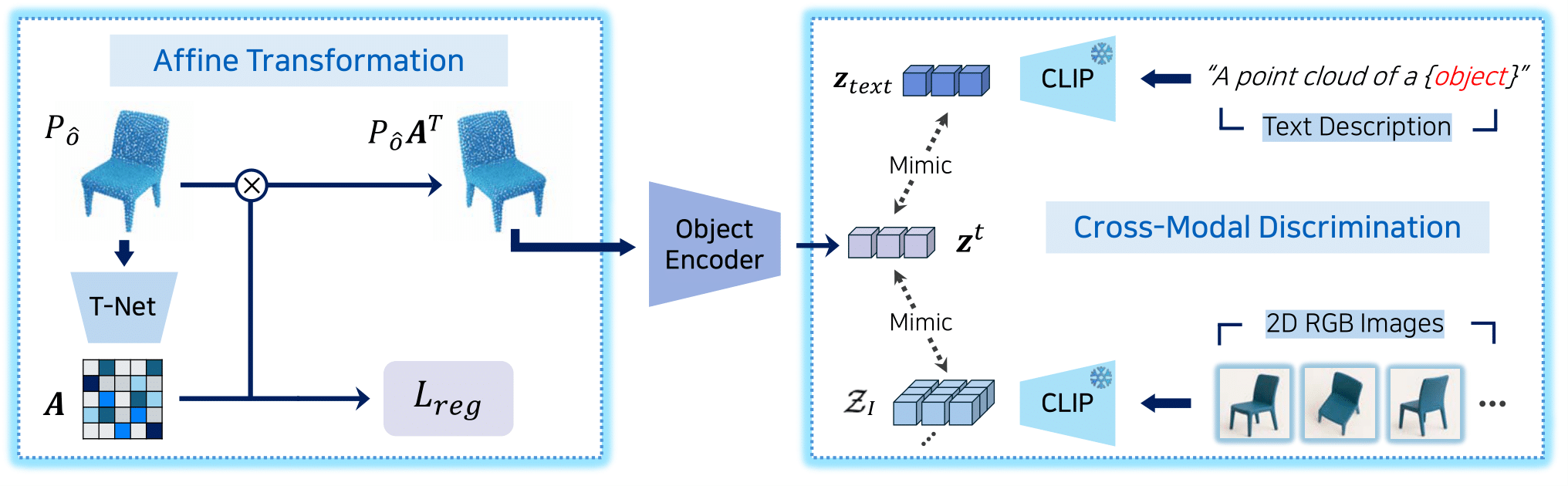
Architecture of first stage (object encoder pretraining): The encoder extracts object embedding from point clouds via affine transformation, aligned with text/visual CLIP features
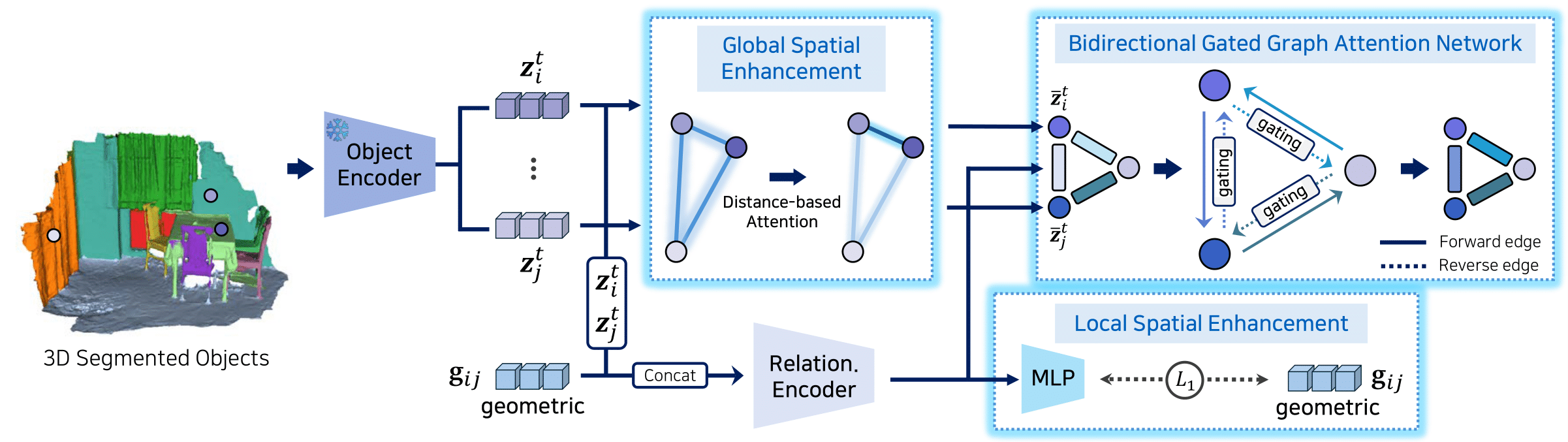
Architecture of second stage (3D semantic scene graph prediction): Object features are refined via Global Spatial Enhancement to incorporate global spatial context based on inter-object distances, producing enhanced features. Simultaneously, the Local Spatial Enhancement locally preserves geometric relationships between object pairs. The Bidirectional Gated Graph Attention Network then selectively modulates the information of reverse edges, effectively capturing asymmetric relationships between objects
3D Scene Graph Prediction
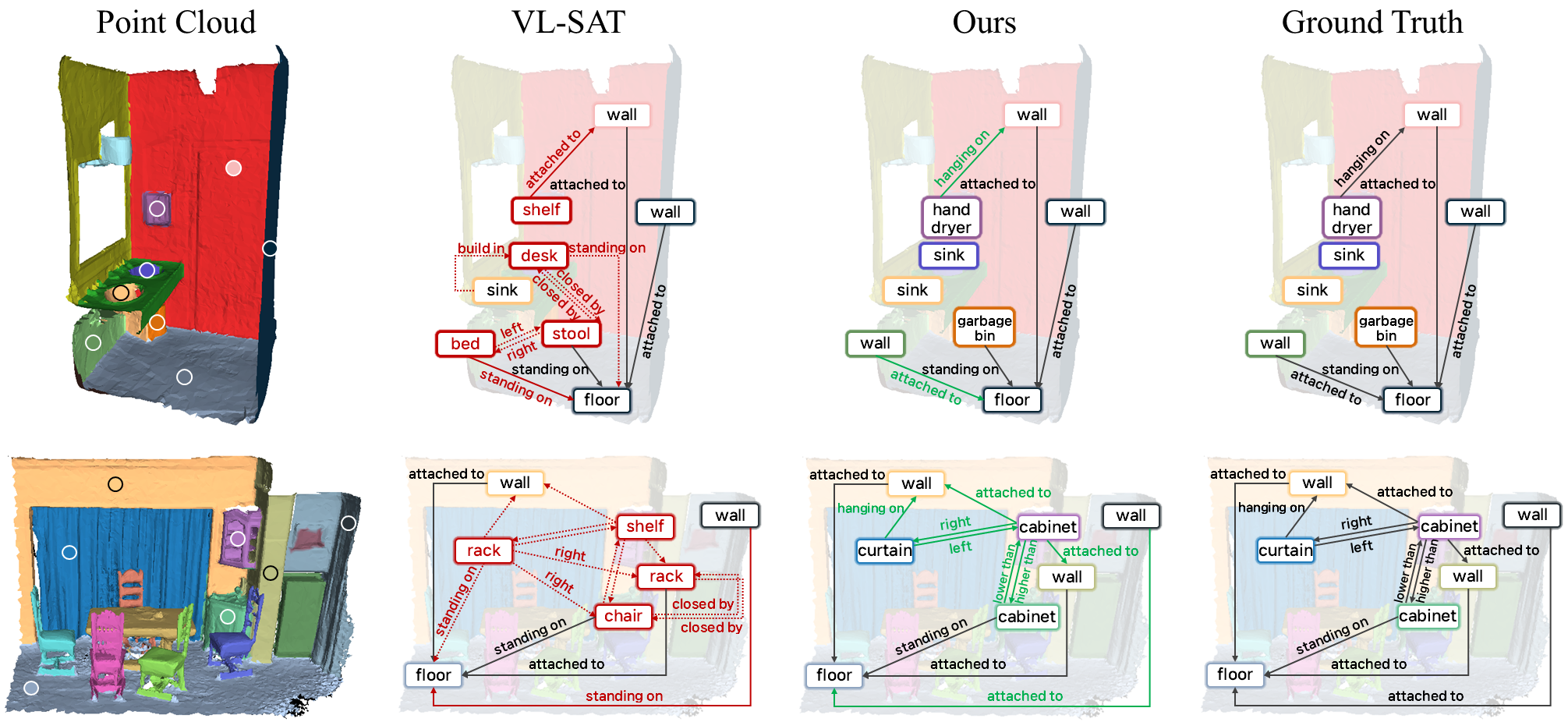
Qualitative comparison between baseline (VL-SAT) and ours: VL-SAT frequently misclassifies visually similar but semantically distinct objects such as cabinet and chair, or stool and garbage bin, which leads to erroneous relationship predictions. In contrast, our method correctly identifies object categories, thereby facilitating accurate and consistent relationship prediction
Object Feature Representation

We visualize the learned object embedding space using t-SNE for the ten most frequent object categories in the dataset. Compared to (a) baseline (VL-SAT), (b) our approach yields more compact and well-separated clusters, particularly for structurally similar object pairs such as ceiling–floor, wall–door, and curtain–window. These results suggest that our object encoder learns more discriminative features, which provide a semantically stronger foundation for subsequent relationship classification
Citation
@article{heo2025object,
title={Object-Centric Representation Learning for Enhanced 3D Scene Graph Prediction},
author={Heo, KunHo and Kim, GiHyun and Kim, SuYeon and Cho, MyeongAh},
journal={arXiv preprint arXiv:2510.04714},
year={2025}
}