Abstract
Architecture
Stage 1. Temporal-aware Vector Quantization

Stage 2. Part-Guided Motion Synthesis

Next, we first applies Part-aware Text Grounding (PTG): a CLIP text embedding is transformed by multiple part-specific MLPs, and a part gate selects the most suitable embedding for each body part. To keep both diversity and semantic consistency, PTG is trained with a contrastive diversity objective and an auxiliary part-text alignment loss. Then the Part-Guided Network generates arm/leg tokens autoregressively and fuses them into Part Guidance over short cycles. The holistic transformer uses this guidance to generate full-body tokens, instead of predicting holistic motion alone. During generation, Holistic-Part Fusion (HPF) continuously injects part tokens into the holistic stream via attention, improving whole-body coordination while preserving fine-grained part expressiveness.
Visualizations

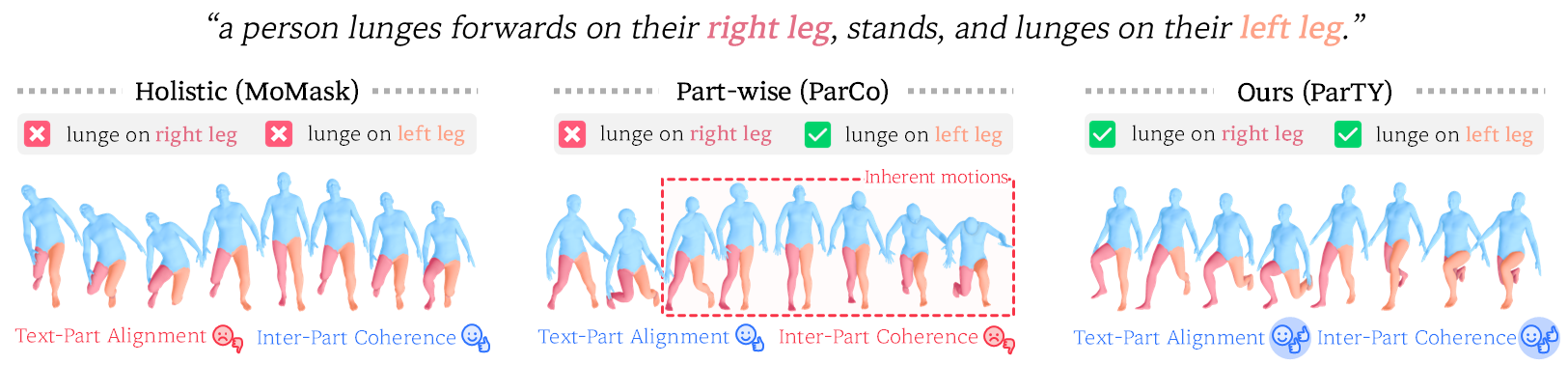
Part-level evaluation. The qualitative analysis shows that ParTY better matches fine-grained part instructions (e.g., specific arm/leg actions) than both holistic (MoMask) and prior part-wise baseline (ParCo). This observation is consistent with the part-level metrics: ParTY improves part-wise text-motion alignment and motion quality for both arms and legs, indicating that part semantics are preserved during generation rather than diluted in full-body synthesis.
Coherence-level evaluation. We also highlights that strong part control alone is insufficient if global coordination collapses. Prior part-wise generation can show artifacts such as neck distortion or mismatched upper/lower body orientation, which lowers temporal and spatial consistency. ParTY maintains synchronized full-body dynamics while executing part-specific motions, reflected by stronger Temporal Coherence (TC) and Spatial Coherence (SC) scores and visually stable poses across frames.